在实际项目中,从Kafka到HDFS的数据是每天自动生成一个文件,按日期区分。而且Kafka在不断生产数据,因此看看kettle是不是需要时刻运行?能不能按照每日自动生成数据文件?
为了测试实际项目中的海豚定时调度从Kafka到HDFS的Kettle任务情况,特地提前跑一下海豚定时调度这个任务,看看到底什么情况,也给大家提供一个参考!
海豚调度任务配置
(一)SHELL脚本配置
#!/bin/bash
source /etc/profile
/opt/install/kettle9.2/data-integration/pan.sh -rep=hurys_linux_kettle_repository -user=admin -pass=admin -dir=/kafka_to_hdfs/ -trans=04_Kafka_to_HDFS_turnratio level=Basic >>/home/log/kettle/04_Kafka_to_HDFS_turnratio_`date +%Y%m%d`.log
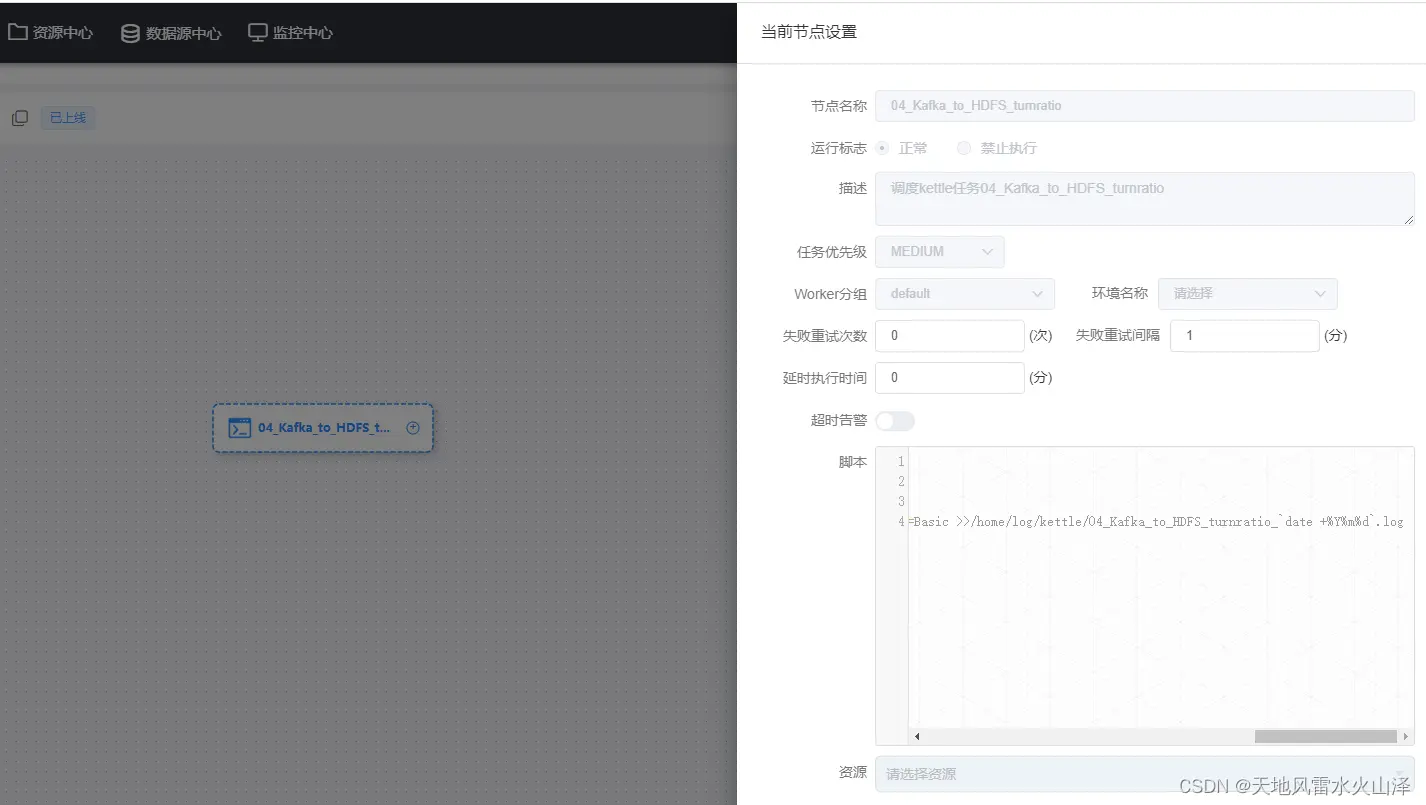
(二)定时任务设置
定时任务设置为每天的零点,零点一到开始执行任务
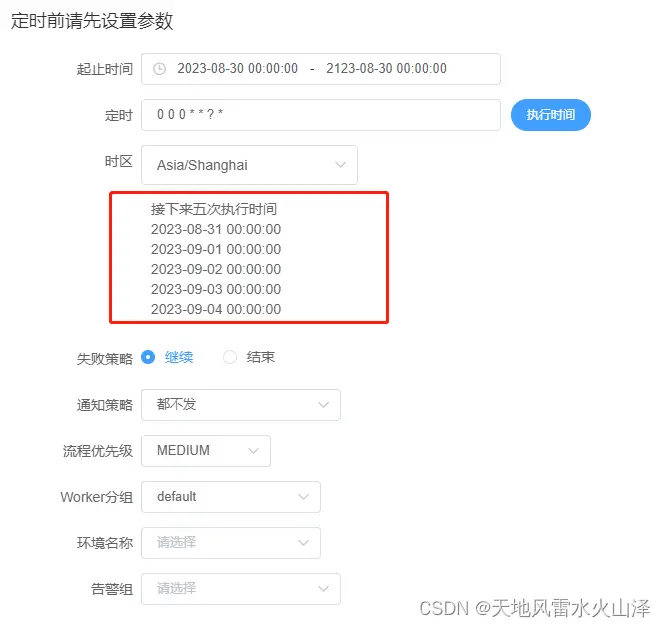
(三)最后工作流情况

启动工作流

工作流启动,成功!工作流一直在跑 
相应的任务实例也在跑!
启动工作流每天HDFS情况
(一)第一天为2023/8/30日
由于第一天开始执行任务,因此自动生成2023/08/30的HDFS文件
(二)第二天为2023/8/31日
2023/08/31早上更新
(1)04_Kafka_to_HDFS_turnratio任务
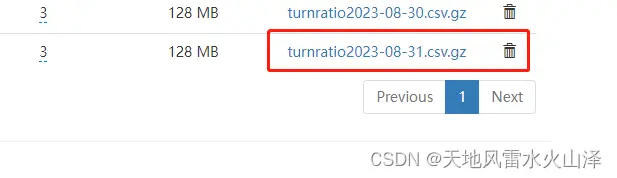 第二天的海豚任务自动调度,自动生成2023/08/31的HDFS文件
第二天的海豚任务自动调度,自动生成2023/08/31的HDFS文件
但问题是,除了再跑31日的任务外,30日的任务还在跑,可能是定时配置有问题,需要优化
而且这样搞容易把kettle搞出问题!

2023/08/31晚上更新
(1)04_Kafka_to_HDFS_turnratio任务
不设置定时任务,kettle任务一直运行,已经生成8月31日的文件,观察明天会不会自动生成9月1日的数据文件

已生成的8月31日文件
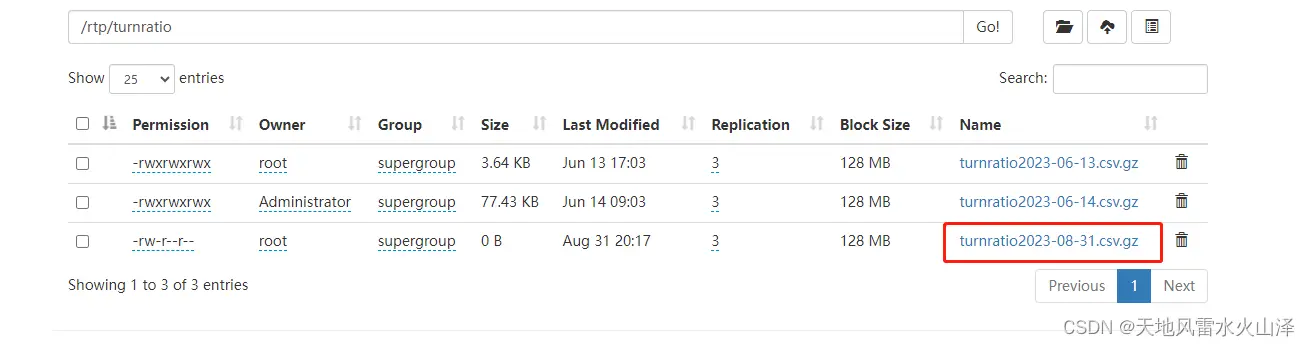
(2)01_Kafka_to_HDFS_queue任务
不设置定时任务,kettle任务一直运行,已经生成8月31日的文件,观察明天会不会自动生成9月1日的数据文件
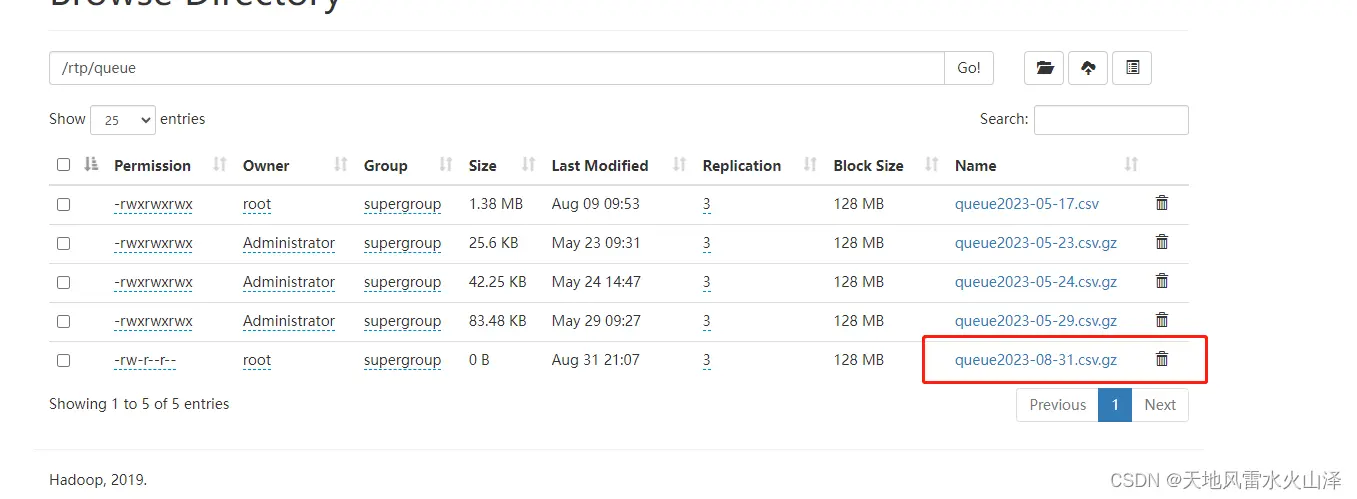
已生成的8月31日文件
如果明早不能自动生成9月1日的文件,那就要设置海豚定时为每天的执行时间为0时0分0秒到23时59分59秒 或者在脚本里设置时间 或者在kettle里设置时间?我们试试看!
(三)第三天为2023/9/1日
2023/09/01早上更新
昨晚海豚调度的两个kettle任务以失败告终,没有自动生成9月1日的数据文件 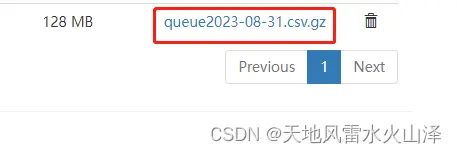 今日再尝试其他的方式
今日再尝试其他的方式
2023/09/01下午更新
下午尝试用Crontab定时任务调度Kettle脚本
\[root@hurys22 kettle\_job\_sh\]# crontab -l
SHELL=/bin/bash
\# */1 * * * * /bin/sh /opt/install/kettle9.2/kettle\_job\_sh/test2.sh
06-07 17 * * * /bin/sh /opt/install/kettle9.2/kettle\_job\_sh/01\_Kafka\_to\_HDFS\_queue.sh 设置每天的17点的6分到7分中执行

但是日志文件显示kettle任务却一直再跑
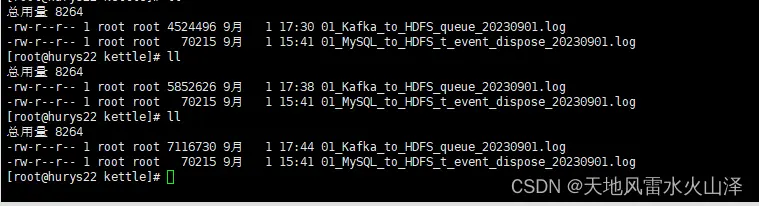
当然,HDFS中确实生成了9月1日今日的文件,而且任务运行时间是我设置的17点7分

这个方法不行,后面再试试其他方法?怎么就不会设置任务停止呢
(四)第四天为2023/9/4日
2023/09/04早上更新
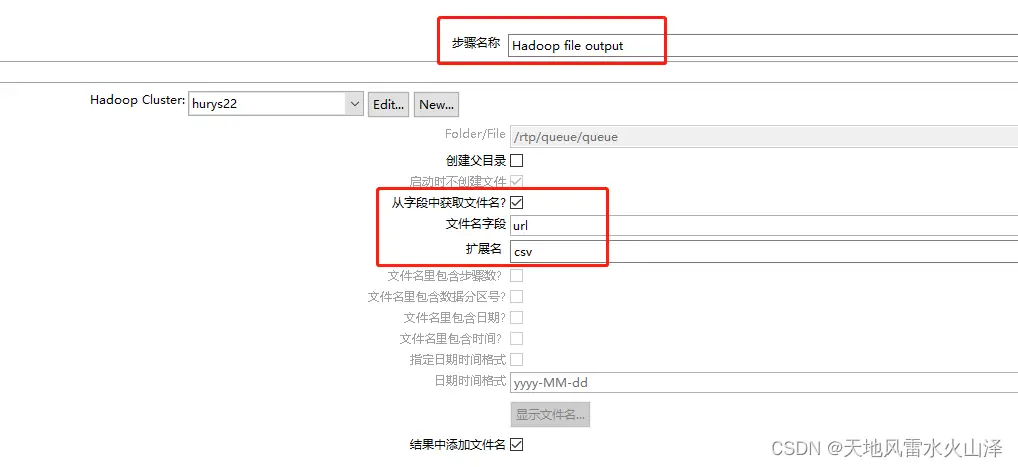
由于Kafka里有时间戳字段,因此在kettle任务里获取当前系统时间戳的日期字段、然后文件名直接从这个日期字段获取
(1)当前系统时间戳的日期字段
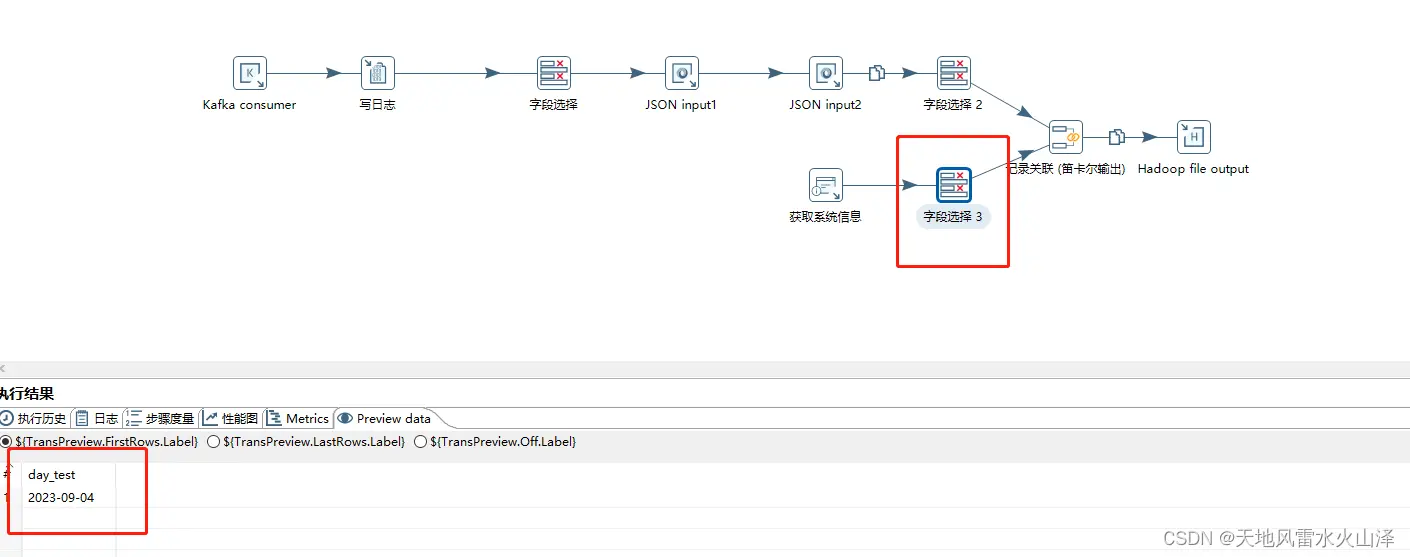
(2)HDFS输出中文件名直接获取这个日期字段,这样kettle任务运行时,是不是能自动生成每天的数据文件?
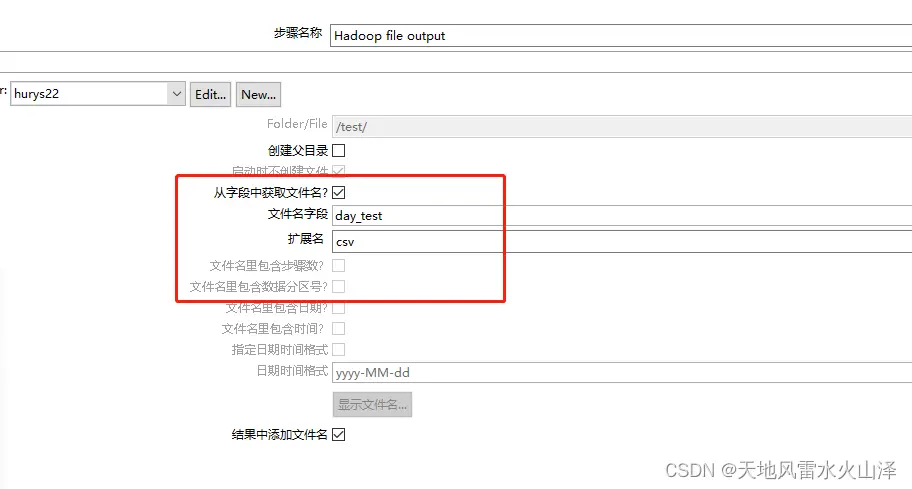
(3)测试结果,任务可以跑通,但是HDFS生成的文件不知却在哪?
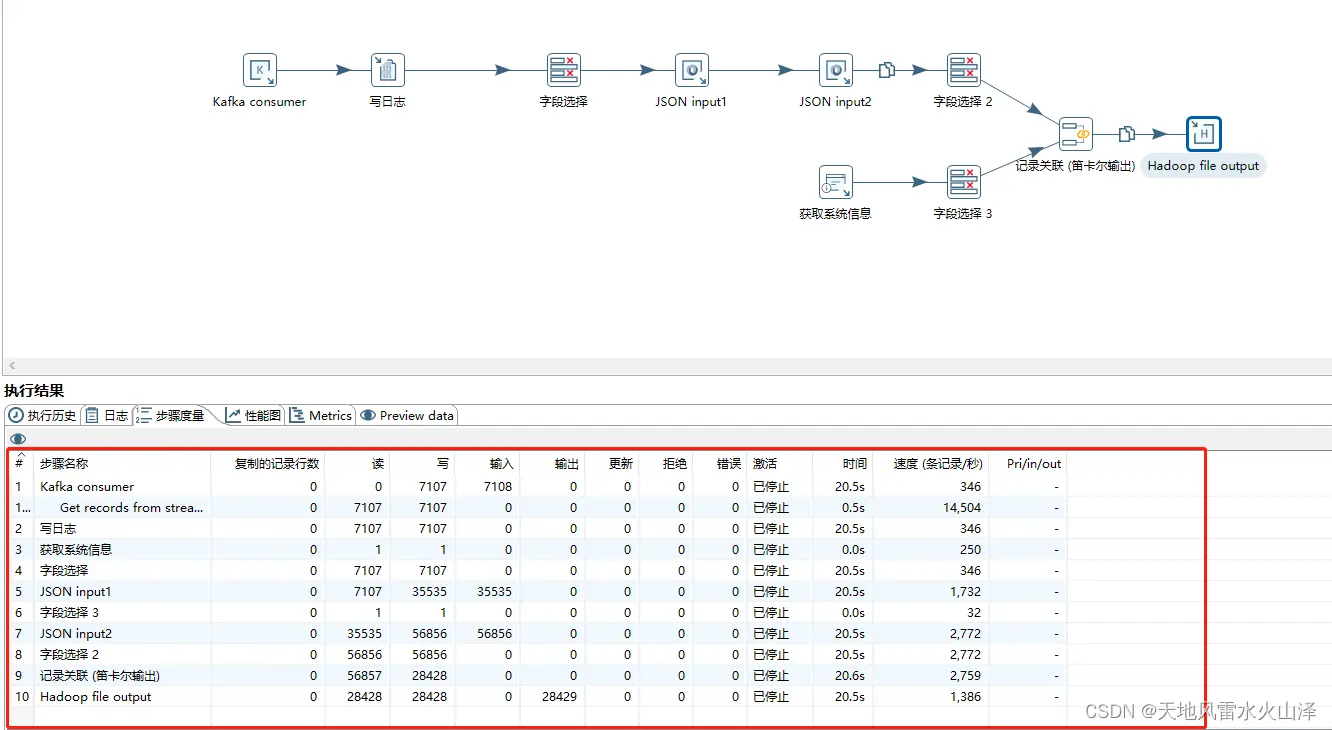
终于查到了,原来这样导出的文件不在HDFS,而在kettle的安装文件里,即在本地
 而且这么直接以日期命名也有问题,因为有多个Kafka,不可能仅仅以日期命名区分
而且这么直接以日期命名也有问题,因为有多个Kafka,不可能仅仅以日期命名区分
2、2023/09/04晚上更新
因为上午的思路有问题,导出的文件没有在HDFS中,反而在本地,于是下午又换了种思路。 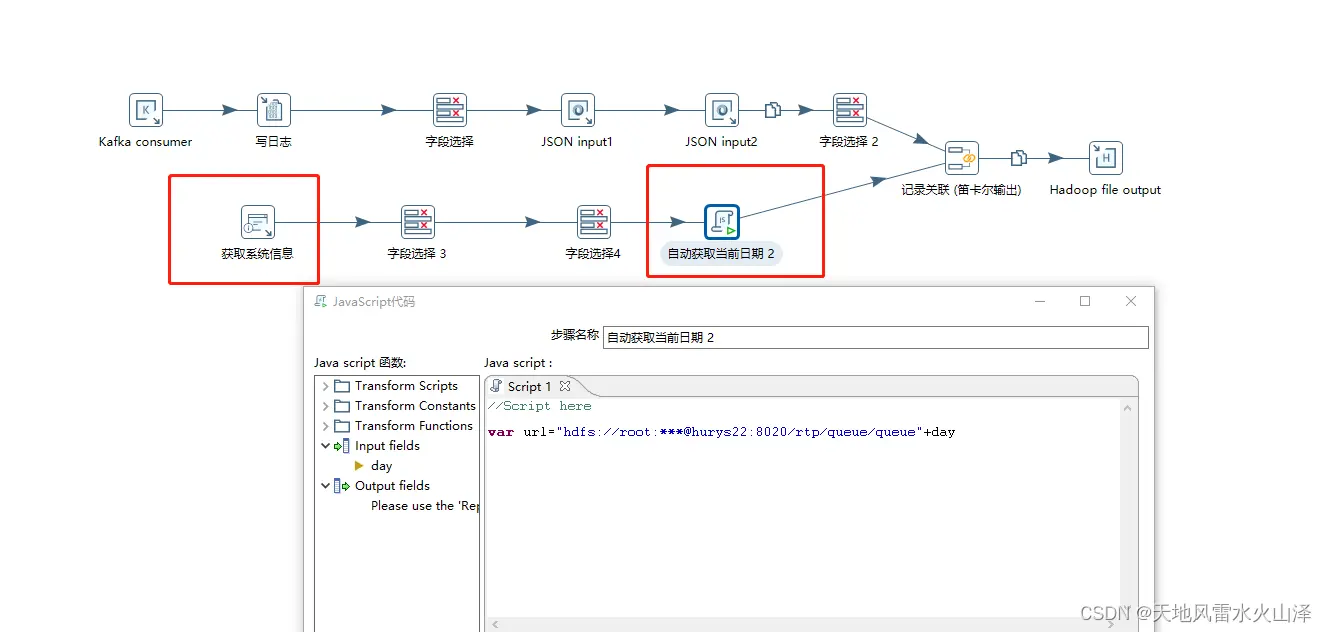
还是从系统获得时间day,但是文件路径直接写成HDFS的文件路径+day,这样的url字段才是HDFS输出控件中的文件名字段
(1)用海豚调度对比,定时调度01_Kafka_to_HDFS_queue任务
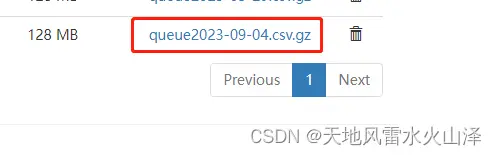
目前已生成生成9月4日的文件
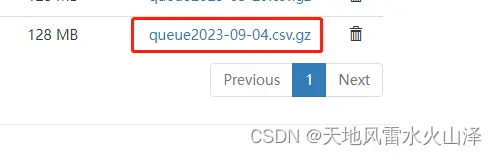
(2)用海豚调度对比,不加定时调度04_Kafka_to_HDFS_turnratio任务  目前已生成生成9月4日的文件
目前已生成生成9月4日的文件
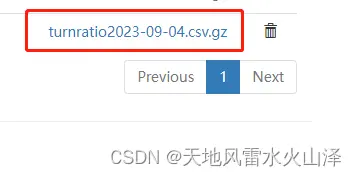
(五)第五天为2023/9/5日
2023/09/05早上更新
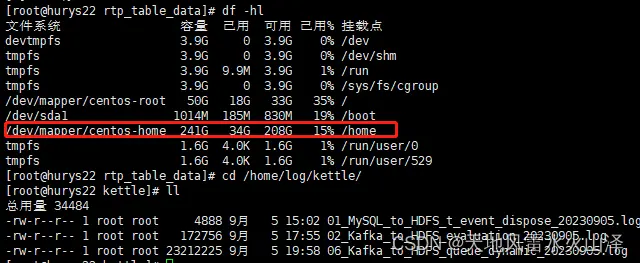
虽然自动生成了9月5日的文件,但是由于数据量过大、加上把hadoop.tmp.dir放在了/opt/soft/hadoop313/hadooptmp,导致opt文件夹磁盘溢出,使得namenode处于安全模式。
花了一上午时间终于解决NameNode的安全模式问题,发现应该把HADOOP 运行时存储路径放在home目录下,因为home的磁盘空间最大
2023/09/05晚上更新
惊喜!!!
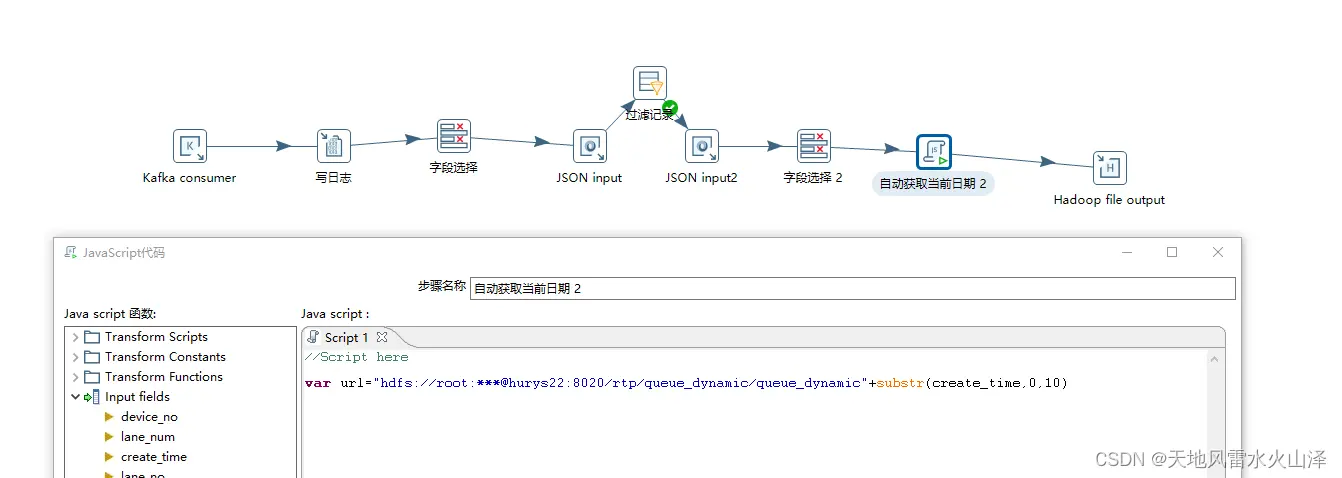
可能已经找到了解决方法,直接对Kafka里的时间戳字段进行截取,然后拼接文件路径,从而形成一个可以根据时间戳字段的日期变动的HDFS文件,即每天自动生成一个数据文件
(1)通过Java自定义文件名 字段url(HDFS路径+截取的可变的时间戳字段)
var url="hdfs://root:***@hurys22:8020/rtp/queue\_dynamic/queue\_dynamic"+substr(create_time,0,10)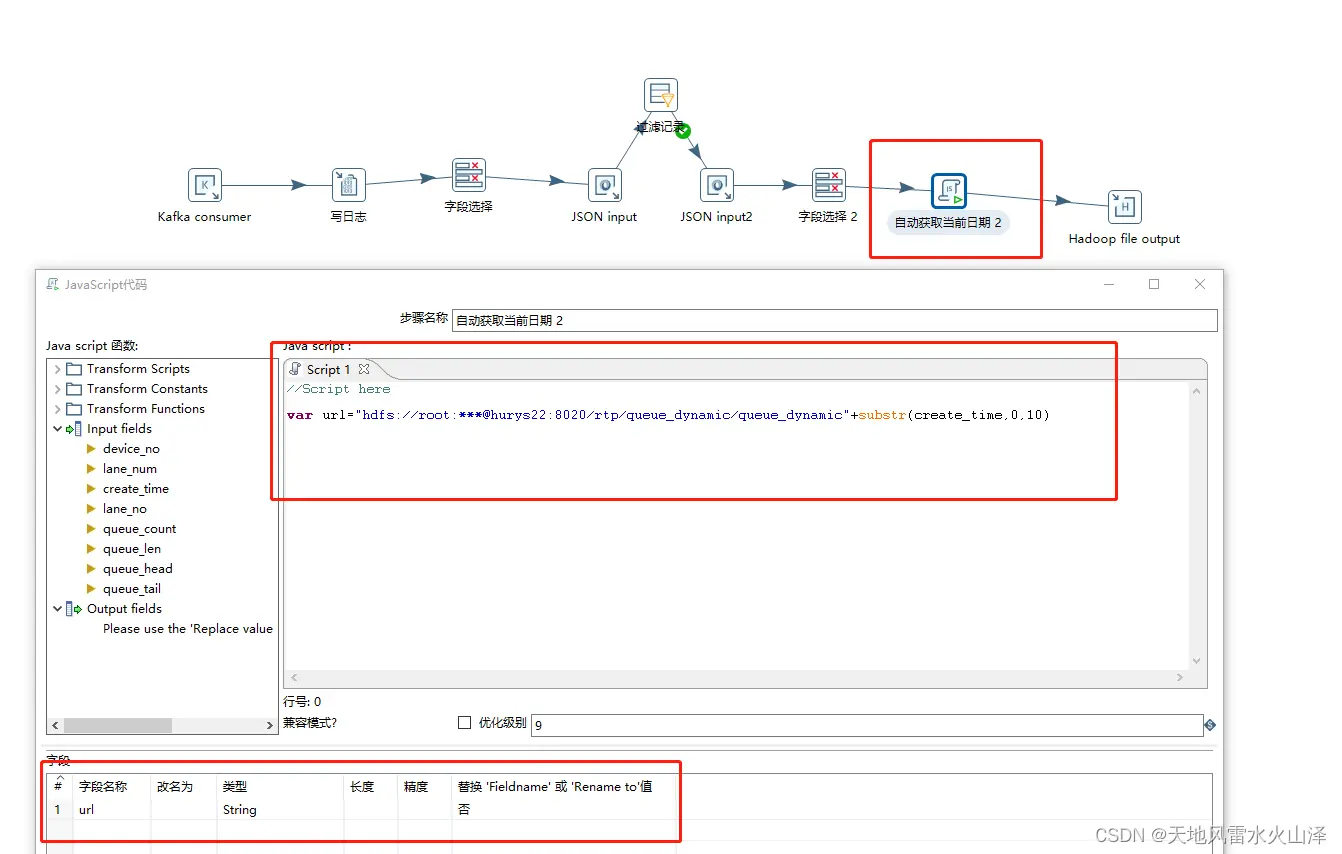
(2)在HDFS输出控件的文件就选择url字段
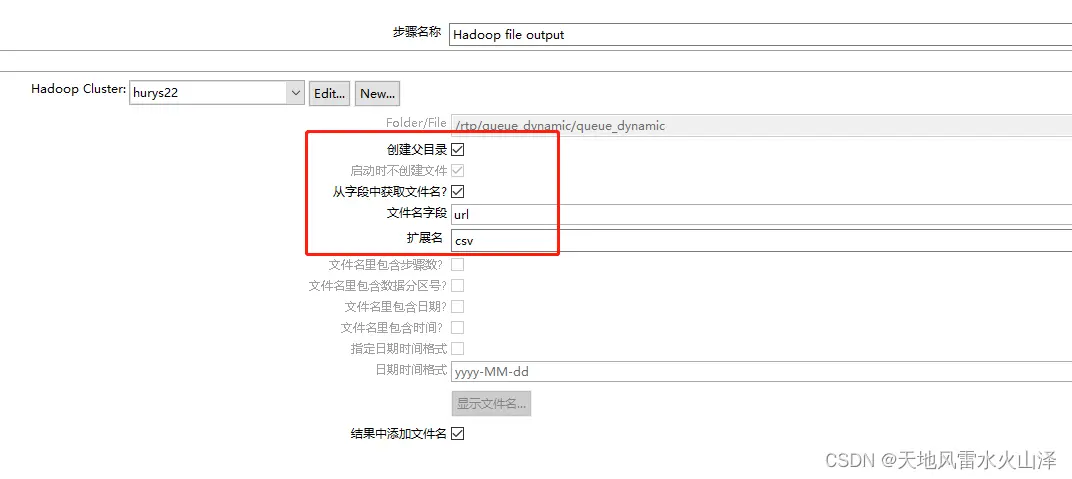 (3)结果
(3)结果
已经生成了9月5日的数据文件,不需要海豚定时调度,只需要海豚一直跑kettle任务即可!
虽然还是生成了9月5日的数据文件,不过我今天下午按照生成每小时维度的数据文件测试过
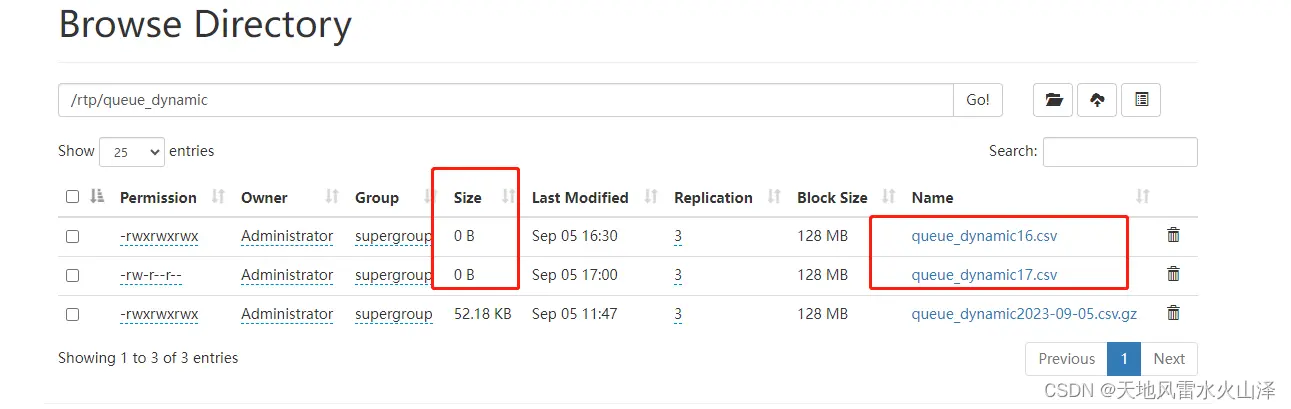
下午16时运行任务,生成了16时的数据文件,然后到17时,又生成了17时的数据文件,这两个数据文件都在跑,而且HDFS里大小显示都为0。
不过区别是,16时的数据是完整的,17时的数据文件是不断增加的。因为Kafka是实时的,17时只会发送17时的数据,不会发送16时数据。下面是16时的文件数据

16时的数据文件是有固定的数据,17点后就没有再写入数据。之所以看不到这个这个block的大小,是因为写入数据的规模太小了,等到这个写入的数据规模达到128MB,即一个块大小后才会看到这个block的数据。
所以只要一直运行这个kettle任务、不断写入数据即可,只要写入的数据规模达到128MB,第一个block就会被看到。
已用海豚调度一个kettle任务,没有定时,就一直跑。目前HDFS已生成了9月5日的数据文件,明天就可以观察几点
1、有没有自动生成明天9月6日的数据文件
2、今天9月5日的数据文件里面的数据是不是固定的、完整的,晚上12点之后不再写入
3、等到写入数据规模达到128MB看第一个block的数据大小可不可看到?
明天9月6日除了看这几点外,还用flume去做Kafka到HDFS的采集工作,以防万一,这两天被这个问题搞得头疼,kettle真是一个易入门难精通的工具!
(六)第六天为2023/9/6日
2023/09/06早上更新
由于昨晚Kafka突然有问题,导致kettle没能导入数据到HDFS的文件,今早已重新启动Kafka服务

(1)目前已重新启动海豚调度的kettle服务

(2)目前已自动生成9月6日的数据文件
(3)只能明天9月7日看一下昨晚的3个问题
1、有没有自动生成明天9月7日的数据文件
2、今天9月6日的数据文件里面的数据是不是固定的、完整的,晚上12点之后不再写入
3、等到写入数据规模达到128MB看第一个block的数据大小可不可看到?
2023/09/06下午更新
(1)为了以防万一,加了个对比测试。看看如果一天的数据放不满一个block或者部分多余数据放不满一个block,可不可以正常显示?即使它总的写入数据量大于128MB
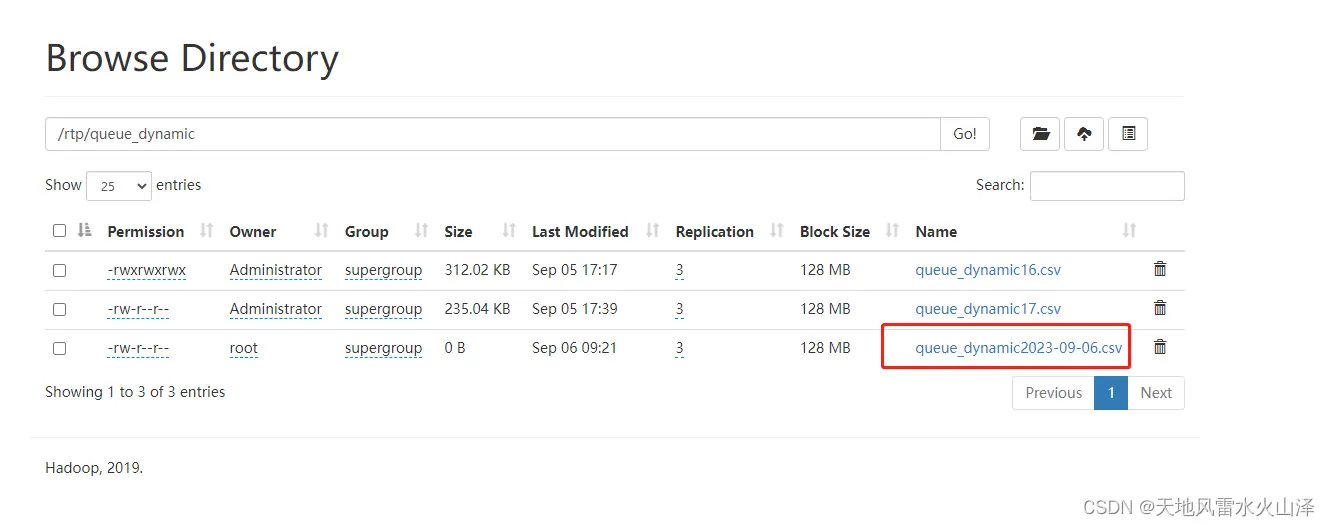
不仅多加了几台模拟设备推送数据,还对动态排队数据和静态排队数据两个kettle任务进行对比
(2)动态排队数据有自动日期分区,可以自动分成不同日期的文件,就是昨晚跑的kettle任务
(3)而静态排队数据没有日期分区,就往第一个日期文件里写入数据
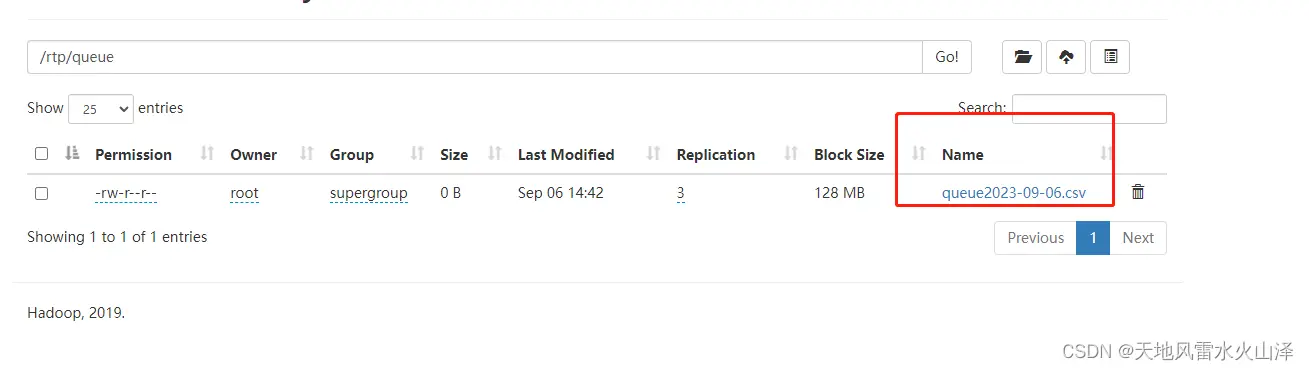
目前静态排队数据也已经生成了9月6日的数据文件,后面会一直写入这个文件
 明早对比这两个kettle任务的数据文件看看情况
明早对比这两个kettle任务的数据文件看看情况
(七)第七天为2023/9/7日
2023/09/07早上更新
A、HDFS文件有日期分区的动态排队数据kettle任务状况
(1)首先是自动生成9月7日的文件
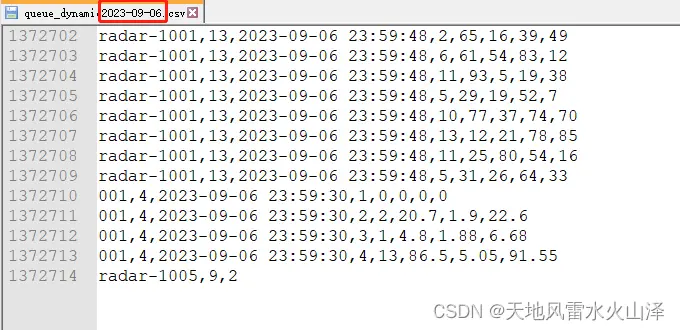 (2)然后是6日的数据文件固定,没有7日的数据
(2)然后是6日的数据文件固定,没有7日的数据
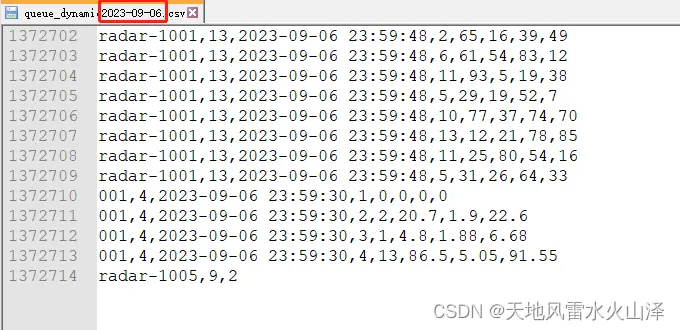
(3)6日的数据这一块由于只有62.8MB,因此HDFS的块没有显示大小

B、HDFS文件没有日期分区的静态排队数据kettle任务状况
由于写入的HDFS文件没有日期分区,而且数据量写入超过了128MB,所以这一块的数据虽然在不断写入,但是这一块的文件显示大小为128MB
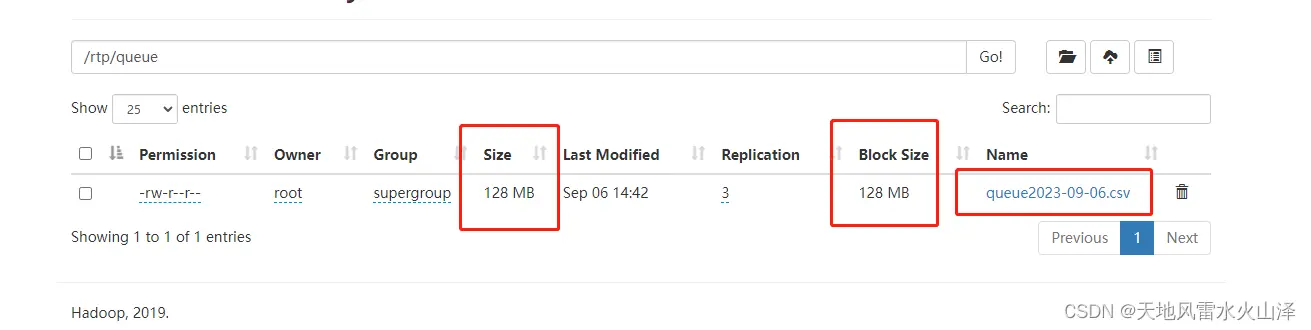 疑问:现在任务依然运行,我想看看这个块已经有128MB后,会不会在其他block写入数据?
疑问:现在任务依然运行,我想看看这个块已经有128MB后,会不会在其他block写入数据?
2023/09/07晚上更新
A、HDFS文件有日期分区的动态排队数据kettle任务状况
(1)今日9月7日写入的数据量超过128MB,因此HDFS已显示文件大小

总结一下:用kettle采集Kafka数据写入HDFS这条路是可行的,只要设置变动的文件名、生成每日的数据文件,然后一直跑任务就好!!!
本文由 白鲸开源科技 提供发布支持!